Fedbcgd: Communication-efficient accelerated block coordinate gradient descent for federated learning
Abstract
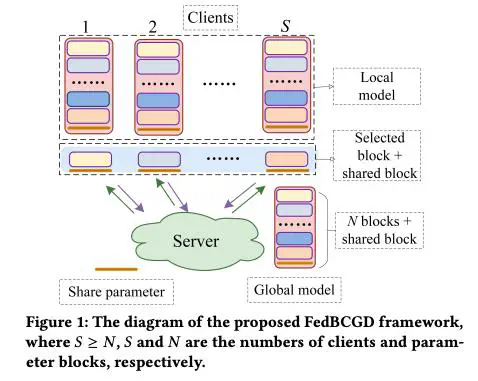
Although federated learning has been widely studied in recent years, there are still high overhead expenses in each communication round for large-scale models such as Vision Transformer. To lower the communication complexity, we propose a novel communication efficient block coordinate gradient descent (FedBCGD) method. The proposed method splits model parameters into several blocks and enables upload a specific parameter block by each client during training, which can significantly reduce communication overhead. Moreover, we also develop an accelerated FedBCGD algorithm (called FedBCGD+) with client drift control and stochastic variance reduction techniques. To the best of our knowledge, this paper is the first parameter block communication work for training large-scale deep models. We also provide the convergence analysis for the proposed algorithms. Our theoretical results show that the communication complexities of our algorithms are a factor lower than those of existing methods, where is the number of parameter blocks, and they enjoy much faster convergence results than their counterparts. Empirical results indicate the superiority of the proposed algorithms compared to state-of-the-art algorithms.